It is interesting how the memory landscape has seen such a surge of solutions over the past year. As agents move from curiosities to workers, the "how do I remember this?" problem has moved to center stage.
But if you look closely, most of these solutions aren't actually solving memory. They are solving retrieval. And they're doing it on a spectrum that forces a frustrating trade-off.
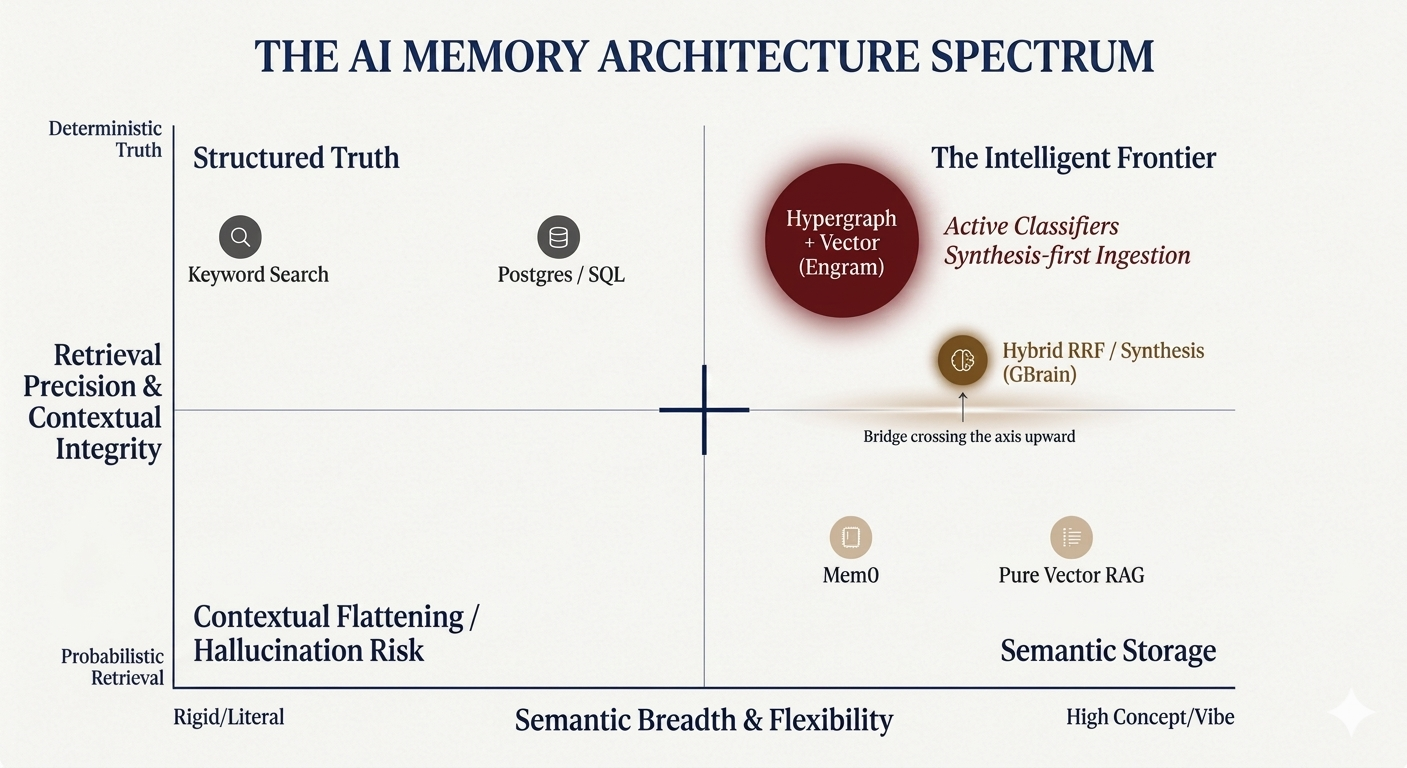
the precision-flexibility trap
Most current solutions can be mapped on a coordinate system. On one side, you have the deterministic databases—SQL, Postgres, Keyword search. These offer high precision but zero semantic flexibility. If you don't search for the exact string, the system is blind.
On the far right, you have pure vector RAG. This offers massive semantic breadth. It understands the "vibe," but it suffers from low precision. It's probabilistic, meaning it's prone to retrieval noise and hallucination.
The core challenge users face today is being forced to choose between "finding the exact word" or "getting the general vibe." Even with hybrid systems, structural context often gets flattened. If you use OpenClaw or Hermes today, you likely already face these frustrations. The agent "remembers" the fact but loses the relationship between the people, dates, and decisions that gave that fact meaning.
synthesis is the bridge
Garry Tan’s recently launched GBrain (which hit GitHub on April 5, 2026) is a strong move toward solving this via synthesis. GBrain focuses on what Garry calls "Compiled Truth" vs. a raw "Timeline." By treating memory as an assessment that is rewritten as evidence changes, we move closer to how humans actually think.
How that actually pans out across benchmarks compared to other "universal" layers like Mem0 will be the real test for horizontal memory. Mem0 has gained massive traction by providing a personalized memory layer for agents, but it still operates primarily on a semantic retrieval model.
verticalization is the destination
My personal belief is that memory solutions will have to be verticalized to reach that "perfect" level of utility. General-purpose stacks struggle with the nuance of specific industries or functions. A "memory" for a software engineer is structurally different from a "memory" for a growth marketer.
At Engram, we are building a memory system specifically for marketers. This isn't just about better search. It’s about tying marketing-specific classifiers directly into the ingestion engine. The system needs to know why a piece of context matters for a brand before it even stores it.
the endgame: hypergraphs and active classifiers
I believe the "solved" state of agentic memory looks like a three-part stack:
- A Hypergraph-based architecture: Traditional graphs connect two points. Hypergraphs use hyperedges to capture n-ary relationships—modeling the complex, multi-layered links between founders, campaigns, and market trends without losing structural integrity.
- Vector Leaf Nodes: We don't throw away the "vibe." We use vectors at the node level to maintain semantic flexibility, allowing for fuzzy matching within a rigid relational structure.
- Active Ingestion Classifiers: Knowledge must be classified for that specific memory's end objectives before ingestion.
While hybrid search is a great middle ground for total recall, it’s still just a compromise. A hypergraph is necessary to preserve the context that RRF can still flatten. By using active classifiers to organize knowledge during ingestion, we can finally break the precision-flexibility trade-off instead of just settling for a hybrid middle ground.
The next great leap in AI won't just be about more parameters. It will be about the integrity of the history we allow our agents to build.